Raphaël Berthier
 |
BrieflyI am a tenure-track researcher (chaire de professeur junior) at Inria Sorbonne Université. I am a member of the Inria project-team Megavolt. Before that, I was a postdoc at EPFL under the supervision of Emmanuel Abbe and Andrea Montanari. I studied non-convex optimization and the theory of neural networks. Even before, I was a PhD student at Inria Paris under the supervision of Francis Bach and Pierre Gaillard. My PhD thesis is a parallel study of convex optimization and gossip algorithms. The best way to learn about this is to look at the summary at the beginning of the manuscript. Here is a short CV. Contact
Lecture notesOptimization for machine learning, M2 level |
Publications and Preprints
R. Berthier, L. Pillaud-Vivien. Incremental learning in mirror flows, 2026, preprint.
[arXiv, hal] [Show Abstract]Abstract: We study mirror flows generated by a convex quadratic loss and a general convex lower semicontinuous mirror potential. We show that, when initialized near the boundary of the domain of the mirror potential, their rescaled trajectories converge to a limiting mirror flow whose potential is the indicator function of the domain. In this limit, the primal variable minimizes the loss over a time-dependent hypothesis set: the subdifferential of the support function of the domain, evaluated at the dual variable. This characterization provides a general mechanism for incremental learning in mirror flows.
R. Berthier. Diagonal linear networks and the lasso regularization path, 2025, preprint.
[arXiv, hal] [Show Abstract]Abstract: Diagonal linear networks are neural networks with linear activation and diagonal weight matrices. Their theoretical interest is that their implicit regularization can be rigorously analyzed: from a small initialization, the training of diagonal linear networks converges to the linear predictor with minimal 1-norm among minimizers of the training loss. In this paper, we deepen this analysis showing that the full training trajectory of diagonal linear networks is closely related to the lasso regularization path. In this connection, the training time plays the role of an inverse regularization parameter. Both rigorous results and simulations are provided to illustrate this conclusion. Under a monotonicity assumption on the lasso regularization path, the connection is exact while in the general case, we show an approximate connection.
P. Marion, R. Berthier, G. Biau, C. Boyer. Attention layers provably solve single-location regression, 2025, International Conference on Learning Representations (ICLR).
[conference version, hal, arXiv] [Show Abstract]Abstract: Attention-based models, such as Transformer, excel across various tasks but lack a comprehensive theoretical understanding, especially regarding token-wise sparsity and internal linear representations. To address this gap, we introduce the single-location regression task, where only one token in a sequence determines the output, and its position is a latent random variable, retrievable via a linear projection of the input. To solve this task, we propose a dedicated predictor, which turns out to be a simplified version of a non-linear self-attention layer. We study its theoretical properties, by showing its asymptotic Bayes optimality and analyzing its training dynamics. In particular, despite the non-convex nature of the problem, the predictor effectively learns the underlying structure. This work highlights the capacity of attention mechanisms to handle sparse token information and internal linear structures.
D. Pushkin, R. Berthier, E. Abbe. On the minimal degree bias in generalization on the unseen for non-boolean functions, 2024, International Conference on Machine Learning (ICML).
[conference version, hal, arXiv] [Show Abstract]Abstract: We investigate the out-of-domain generalization of random feature (RF) models and Transformers. We first prove that in the ‘generalization on the unseen (GOTU)’ setting, where training data is fully seen in some part of the domain but testing is made on another part, and for RF models in the small feature regime, the convergence takes place to interpolators of minimal degree as in the Boolean case (Abbe et al., 2023). We then consider the sparse target regime and explain how this regime relates to the small feature regime, but with a different regularization term that can alter the picture in the non-Boolean case. We show two different outcomes for the sparse regime with q-ary data tokens: (1) if the data is embedded with roots of unities, then a min-degree interpolator is learned like in the Boolean case for RF models, (2) if the data is not embedded as such, e.g., simply as integers, then RF models and Transformers may not learn minimal degree interpolators. This shows that the Boolean setting and its roots of unities generalization are special cases where the minimal degree interpolator offers a rare characterization of how learning takes place. For more general integer and real-valued settings, a more nuanced picture remains to be fully characterized.
P. Marion, R. Berthier. Leveraging the two timescale regime to demonstrate convergence of neural networks, 2023, Advances in Neural Information Processing Systems (NeurIPS).
[conference version, arXiv] [Show Abstract]Abstract: We study the training dynamics of shallow neural networks, in a two-timescale regime in which the stepsizes for the inner layer are much smaller than those for the outer layer. In this regime, we prove convergence of the gradient flow to a global optimum of the non-convex optimization problem in a simple univariate setting. The number of neurons need not be asymptotically large for our result to hold, distinguishing our result from popular recent approaches such as the neural tangent kernel or mean-field regimes. Experimental illustration is provided, showing that the stochastic gradient descent behaves according to our description of the gradient flow and thus converges to a global optimum in the two-timescale regime, but can fail outside of this regime.
R. Berthier, A. Montanari, K. Zhou. Learning time-scales in two-layers neural networks, 2023, Foundations of Computational Mathematics (FoCM).
[journal, arXiv] [Show Abstract]Abstract: Gradient-based learning in multi-layer neural networks displays a number of striking features. In particular, the decrease rate of empirical risk is non-monotone even after averaging over large batches. Long plateaus in which one observes barely any progress alternate with intervals of rapid decrease. These successive phases of learning often take place on very different time scales. Finally, models learnt in an early phase are typically ‘simpler’ or ‘easier to learn’ although in a way that is difficult to formalize. Although theoretical explanations of these phenomena have been put forward, each of them captures at best certain specific regimes. In this paper, we study the gradient flow dynamics of a wide two-layer neural network in high-dimension, when data are distributed according to a single-index model (i.e., the target function depends on a one-dimensional projection of the covariates). Based on a mixture of new rigorous results, non-rigorous mathematical derivations, and numerical simulations, we propose a scenario for the learning dynamics in this setting. In particular, the proposed evolution exhibits separation of timescales and intermittency. These behaviors arise naturally because the population gradient flow can be recast as a singularly perturbed dynamical system.
R. Berthier. Incremental learning in diagonal linear networks, 2023, Journal of Machine Learning Research (JMLR).
[journal, arXiv] [Show Abstract]Abstract: Diagonal linear networks (DLNs) are a toy simplification of artificial neural networks; they consist in a quadratic reparametrization of linear regression inducing a sparse implicit regularization. In this paper, we describe the trajectory of the gradient flow of DLNs in the limit of small initialization. We show that incremental learning is effectively performed in the limit: coordinates are successively activated, while the iterate is the minimizer of the loss constrained to have support on the active coordinates only. This shows that the sparse implicit regularization of DLNs decreases with time. This work is restricted to the underparametrized regime with anti-correlated features for technical reasons.
R. Berthier, M. B. Li. Acceleration of gossip algorithms through the Euler-Poisson-Darboux equation, 2022, the IMA Journal of Applied Mathematics.
[journal, arXiv] [Show Abstract]Abstract: Gossip algorithms and their accelerated versions have been studied exclusively in discrete time on graphs. In this work, we take a different approach, and consider the scaling limit of gossip algorithms in both large graphs and large number of iterations. These limits lead to well-known partial differential equations (PDEs) with insightful properties. On lattices, we prove that the non-accelerated gossip algorithm of Boyd et al. [2006] converges to the heat equation, and the accelerated Jacobi polynomial iteration of Berthier et al. [2020] converges to the Euler-Poisson-Darboux (EPD) equation - a damped wave equation. Remarkably, with appropriate parameters, the fundamental solution of the EPD equation has the ideal gossip behaviour: a uniform density over an ellipsoid, whose radius increases at a rate proportional to t - the fastest possible rate for locally communicating gossip algorithms. This is in contrast with the heat equation where the density spreads on a typical scale of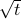 . Additionally, we provide simulations demonstrating that the gossip algorithms are accurately approximated by their limiting PDEs.
. Additionally, we provide simulations demonstrating that the gossip algorithms are accurately approximated by their limiting PDEs.
C. Gerbelot, R. Berthier. Graph-based approximate message passing iterations, 2021, Information and Inference: a Journal of the IMA.
[journal, arXiv] [Show Abstract]Abstract: Approximate-message passing (AMP) algorithms have become an important element of high-dimensional statistical inference, mostly due to their adaptability and concentration properties, the state evolution (SE) equations. This is demonstrated by the growing number of new iterations proposed for increasingly complex problems, ranging from multi-layer inference to low-rank matrix estimation with elaborate priors. In this paper, we address the following questions: is there a structure underlying all AMP iterations that unifies them in a common framework? Can we use such a structure to give a modular proof of state evolution equations, adaptable to new AMP iterations without reproducing each time the full argument ? We propose an answer to both questions, showing that AMP instances can be generically indexed by an oriented graph. This enables to give a unified interpretation of these iterations, independent from the problem they solve, and a way of composing them arbitrarily. We then show that all AMP iterations indexed by such a graph admit rigorous SE equations, extending the reach of previous proofs, and proving a number of recent heuristic derivations of those equations. Our proof naturally includes non-separable functions and we show how existing refinements, such as spatial coupling or matrix-valued variables, can be combined with our framework.
M. Even, R. Berthier, F. Bach, N. Flammarion, P. Gaillard, H. Hendrikx, L. Massoulié, A. Taylor. A continuized view on Nesterov acceleration for stochastic gradient descent and randomized gossip, 2021, oustanding paper award and oral at Advances in Neural Information Processing Systems (NeurIPS).
[conference version, arXiv, an introductory blog post] [Show Abstract]Abstract: We introduce the continuized Nesterov acceleration, a close variant of Nesterov acceleration whose variables are indexed by a continuous time parameter. The two variables continuously mix following a linear ordinary differential equation and take gradient steps at random times. This continuized variant benefits from the best of the continuous and the discrete frameworks: as a continuous process, one can use differential calculus to analyze convergence and obtain analytical expressions for the parameters; and a discretization of the continuized process can be computed exactly with convergence rates similar to those of Nesterov original acceleration. We show that the discretization has the same structure as Nesterov acceleration, but with random parameters. We provide continuized Nesterov acceleration under deterministic as well as stochastic gradients, with either additive or multiplicative noise. Finally, using our continuized framework and expressing the gossip averaging problem as the stochastic minimization of a certain energy function, we provide the first rigorous acceleration of asynchronous gossip algorithms.
R. Berthier, F. Bach, P. Gaillard. Tight nonparametric convergence rates for stochastic gradient descent under the noiseless linear model, 2020, Advances in Neural Information Processing Systems (NeurIPS).
[conference version, hal, arXiv] [Show Abstract]Abstract: In the context of statistical supervised learning, the noiseless linear model assumes that there exists a deterministic linear relation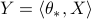 between the random output
between the random output 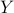 and the random feature vector
and the random feature vector 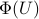 , a potentially non-linear transformation of the inputs
, a potentially non-linear transformation of the inputs 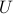 . We analyze the convergence of single-pass, fixed step-size stochastic gradient descent on the least-square risk under this model. The convergence of the iterates to the optimum
. We analyze the convergence of single-pass, fixed step-size stochastic gradient descent on the least-square risk under this model. The convergence of the iterates to the optimum 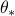 and the decay of the generalization error follow polynomial convergence rates with exponents that both depend on the regularities of the optimum and of the feature vectors . We interpret our result in the reproducing kernel Hilbert space framework; as a special case, we analyze an online algorithm for estimating a real function on the unit interval from the noiseless observation of its value at randomly sampled points. The convergence depends on the Sobolev smoothness of the function and of a chosen kernel. Finally, we apply our analysis beyond the supervised learning setting to obtain convergence rates for the averaging process (a.k.a. gossip algorithm) on a graph depending on its spectral dimension.
and the decay of the generalization error follow polynomial convergence rates with exponents that both depend on the regularities of the optimum and of the feature vectors . We interpret our result in the reproducing kernel Hilbert space framework; as a special case, we analyze an online algorithm for estimating a real function on the unit interval from the noiseless observation of its value at randomly sampled points. The convergence depends on the Sobolev smoothness of the function and of a chosen kernel. Finally, we apply our analysis beyond the supervised learning setting to obtain convergence rates for the averaging process (a.k.a. gossip algorithm) on a graph depending on its spectral dimension.
R. Berthier, F. Bach, P. Gaillard. Accelerated gossip in networks of given dimension using Jacobi polynomial iterations, 2020, SIAM Journal on Mathematics of Data Science (SIMODS).
[journal, hal, arXiv] [Show Abstract]Abstract: Consider a network of agents connected by communication links, where each agent holds a real value. The gossip problem consists in estimating the average of the values diffused in the network in a distributed manner. We develop a method solving the gossip problem that depends only on the spectral dimension of the network, that is, in the communication network set-up, the dimension of the space in which the agents live. This contrasts with previous work that required the spectral gap of the network as a parameter, or suffered from slow mixing. Our method shows an important improvement over existing algorithms in the non-asymptotic regime, i.e., when the values are far from being fully mixed in the network. Our approach stems from a polynomial-based point of view on gossip algorithms, as well as an approximation of the spectral measure of the graphs with a Jacobi measure. We show the power of the approach with simulations on various graphs, and with performance guarantees on graphs of known spectral dimension, such as grids and random percolation bonds. An extension of this work to distributed Laplacian solvers is discussed. As a side result, we also use the polynomial-based point of view to show the convergence of the message passing algorithm for gossip of Moallemi & Van Roy on regular graphs. The explicit computation of the rate of the convergence shows that message passing has a slow rate of convergence on graphs with small spectral gap.
R. Berthier, A. Montanari, P.-M. Nguyen. State evolution for approximate message passing with non-separable functions, 2017, Information and Inference: a Journal of the IMA.
[journal, arXiv] [Show Abstract]Abstract: Given a high-dimensional data matrix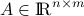 , Approximate Message Passing (AMP) algorithms construct sequences of vectors
, Approximate Message Passing (AMP) algorithms construct sequences of vectors 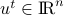 ,
, 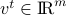 , indexed by
, indexed by 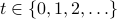 by iteratively applying
by iteratively applying 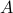 or
or 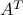 , and suitable non-linear functions, which depend on the specific application. Special instances of this approach have been developed –among other applications– for compressed sensing reconstruction, robust regression, Bayesian estimation, low-rank matrix recovery, phase retrieval, and community detection in graphs. For certain classes of random matrices , AMP admits an asymptotically exact description in the high-dimensional limit
, and suitable non-linear functions, which depend on the specific application. Special instances of this approach have been developed –among other applications– for compressed sensing reconstruction, robust regression, Bayesian estimation, low-rank matrix recovery, phase retrieval, and community detection in graphs. For certain classes of random matrices , AMP admits an asymptotically exact description in the high-dimensional limit 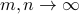 , which goes under the name of ‘state evolution.’
Earlier work established state evolution for separable non-linearities (under certain regularity conditions). Nevertheless, empirical work demonstrated several important applications that require non-separable functions. In this paper we generalize state evolution to Lipschitz continuous non-separable nonlinearities, for Gaussian matrices . Our proof makes use of Bolthausen's conditioning technique along with several approximation arguments. In particular, we introduce a modified algorithm (called LAMP for Long AMP) which is of independent interest.
, which goes under the name of ‘state evolution.’
Earlier work established state evolution for separable non-linearities (under certain regularity conditions). Nevertheless, empirical work demonstrated several important applications that require non-separable functions. In this paper we generalize state evolution to Lipschitz continuous non-separable nonlinearities, for Gaussian matrices . Our proof makes use of Bolthausen's conditioning technique along with several approximation arguments. In particular, we introduce a modified algorithm (called LAMP for Long AMP) which is of independent interest.
PhD thesis
R. Berthier. Analysis and acceleration of gradient descents and gossip algorithms, 2021, manuscript.